7 A/B Testing Questions and Answers in Data Science Interviews
Feb 14, 2023
Tech companies often use A/B tests to make product launch decisions, and if you want to be a data scientist with these companies, you will be expected to conduct these tests.
In fact, A/B testing is one of the main components you should expect to be tested on in interviews.
In this article, we will go over the different stages of A/B testing and what you need to know to answer questions in interviews.
Before a Test
A/B tests are great, but they are not practical to run for every single idea. Oftentimes you will need to select which ideas are worth testing before starting an A/B test.
There are two basic approaches to selecting an idea: quantitative and qualitative analysis.
For quantitative analysis, we can use historical data to determine the opportunity sizing of each idea. This means that using data we already have we can predict the potential impact of the idea.
Qualitative analysis uses focus groups and surveys to gather data directly from users.
Designing an A/B Test
Once we have decided to run an A/B test, we need to determine how long the test will be and what the randomization unit will be.
How Long Will the Test Be?
To figure out how long to run the test, we need to know the sample size, which requires three parameters:
- Type II error rate β or Power (because Power = 1 - β if you know one of them, you know the other)
- Significance level α
- Minimum detectable effect
The rule of thumb formula for sample size is that sample size n is 16 (based on α = 0.05 and β = 0.8) multiplied by sample variance divided by δ square, whereas δ is the difference between treatment and control:
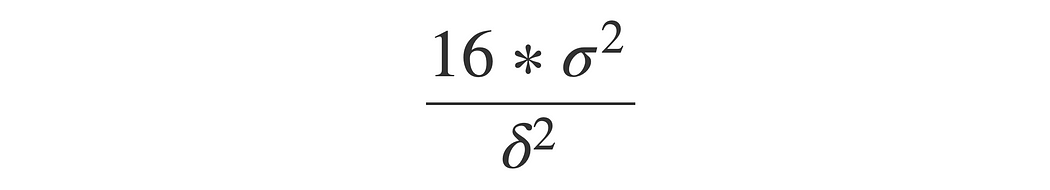
This formula is from Trustworthy Online Controlled Experiments by Ron Kohavi, Diane Tang and Ya Xu.
In an interview, you will just need to explain how to get each parameter and how that parameter affects sample size.
You can get sample variance from the existing data but to estimate δ (the difference between the treatment and control) you will need the last parameter: minimum detectable effect. This is the smallest difference that would matter in practice. This value will be determined by multiple stakeholders.
Once you have the sample size you can calculate how long to run the experiment by dividing the sample size by the number of users per group.
However, you should always run the experiment for at least seven days, and two weeks is recommended. Remember that more is better than not enough, especially when gathering data.
Randomization Unit and Network Effect
Usually, in an A/B test, the control and treatment groups are created by randomly selecting users. This is done under the assumption that each user is independent and that there will be no interference between the control and treatment groups, but sometimes this independence assumption is not true.
One reason for this is network effect. On social networks, a user’s behavior will be impacted by those they interact with. This can cause the effect on the treatment group to spill into the control group If users in the treatment group are in the social network of those in the control group. This will underestimate the treatment effect.
Two-sided marketplaces also experience interference between the control and treatment groups. This is because in a two-sided marketplace the control and treatment groups will be competing for the same resources, and that will lead to an overestimation of the treatment effect.
To deal with this interference, you can design an A/B test to isolate the users in each group.
For social networks, two common solutions are network clusters (explained here) and ego-cluster randomization (explained here).
For two-sided marketplaces, we can use geo-based randomization (this isolates users by creating groups based on location but it also creates a larger variance) or time-based randomization (this creates isolation by selecting a random time to use the treatment but is only practical when the treatment takes a short time) to deal with interference.
Analyzing Results
Once you have finished running the test, you need to make sure that you have quality results. There are several things that can skew your results.
Primacy and Novelty Effects
Some people dislike change (primacy effect), and others like something just because it's new (novelty effect). Both of these kinds of people will have an initial impact on the results of the treatment that can be misleading.
There are a few ways to deal with primacy and novelty effect. One way is to simply target first-time users because these effects will obviously not occur with them.
If we want to check for primacy and novelty effects on a test that is already running, we can compare the results of new users In both the control and treatment group or compare first-time users’ results with existing users’ results in the treatment group.
Multiple Testing Problem
Another thing to consider when analyzing results is the multiple testing problem. Simple A/B tests have just 2 groups: A (control) and B (treatment). However, in some cases there might be multiple variants we want to test at once, so we will have more than one treatment group.
Multiple treatment groups are a problem because it increases the chance of false discoveries. This means that 0.05 is not a good significance level when there are multiple treatment groups.
There are a few ways to approach fixing this.
You could use the Bonferroni correction, which means dividing the normal significance level of 0.05 by the number of tests. However, this method can be too conservative.
Another method is to control the false discovery rate (FDR):
FDR = E[# of false positive / # of rejections]
The FDR measures how many metrics made a real difference compared to those that were false positives. It is based on the metrics that you declare to have a statistically significant difference. This method only works well in instances where you have a huge number of metrics.
Making Decisions
In an ideal world, the A/B test results would show a practically significant difference, and we could feel good about launching the feature.
Sometimes though we get contradicting results where one metric goes up while another metric goes down. What do you suggest in these cases?
The reality is that these types of decisions are influenced by a lot of factors. For answering a question in an interview though, it is helpful to focus on the current objective of the experiment while also quantifying the negative impact to make a decision. If the results are improving the current focus and the negative impact is acceptable, you can likely suggest moving forward with launch.
Before You Go…
Remember that A/B tests are a large part of what data scientists do, so you want to be comfortable answering questions about them in your interviews.
If you want to read a longer version of this post with more examples, you can find that here.
